Mustango: Toward Controllable Text-to-Music Generation
Melechovsky, Jan, Zixun Guo, Deepanway Ghosal, Navonil Majumder, Dorien Herremans, and Soujanya Poria. “Mustango: Toward Controllable Text-to-Music Generation.” arXiv:2311.08355. Preprint, arXiv, June 3, 2024. https://doi.org/10.48550/arXiv.2311.08355.
Table of Contents
Mustango is a diffusion-based text-to-music generation system that goes beyond general text conditioning. It introduces fine-grained control over musical attributes such as chords, beats, tempo, and key, enabling more structured and musically meaningful audio synthesis from natural language prompts.
MuNet: Music-Aware UNet Denoiser
At the core of Mustango is MuNet, a music-domain-informed UNet module that guides the reverse diffusion process. It integrates:
- General text embeddings (from FLAN-T5), and
-
Predicted musical features (chords, beats, etc.) via hierarchical cross-attention layers.
This enables Mustango to generate music that faithfully follows the structural elements described in the input text.
MusicBench: A Richly Augmented Dataset
To train controllable models, the authors introduce MusicBench, a dataset built on top of MusicCaps with:
- Over 52,000 samples
- Text captions enhanced with automatically extracted and paraphrased descriptions of chords, tempo, key, and rhythm
- Audio augmentations including pitch shifts, tempo changes, and volume variations
Challenges in Diffusion-based Music Generation
- Musical structure enforcement: Music must obey formal rules like key signatures and chord progressions, which are difficult to evaluate and condition on.
- Data scarcity: High-quality paired text-music datasets are limited and often lack rich musical annotations.
- Representational depth: Most captions lack structural and harmonic detail. Mustango tackles this by learning to infer and control these aspects from text.
Fundamentals of Music
To understand musical features, we will use "We Will Rock You" by Queen as our example, assuming we have no prior music knowledge.
What is Music Made Of?
Think of music like a recipe with four main ingredients:
- Beats = The steady pulse (like your heartbeat)
- Chords = Multiple notes played together (like harmony)
- Key = The musical "home base"
- Tempo = How fast or slow the music moves
1. Beats and Downbeats - The Musical Heartbeat
A beat is like the steady tick of a clock in music. It's the pulse you naturally tap your foot to.
The most common time signature is 4/4, which means:
- 4 beats per measure
- Each beat gets a quarter note duration
A measure is a recurring pattern of beats that creates the rhythmic structure of music. Think of it as a rhythmic "sentence" that repeats throughout the song.
Beat Type 1 | Beat Type 2 | Beat Type 3 | Beat Type 4
↓ ↓ ↓ ↓
STRONG weak medium weak
(downbeat)
Beat: 1 2 3 4 | 1 2 3 4 Pattern: STOMP STOMP CLAP -- | STOMP STOMP CLAP -- Sound: "WE" "WILL" "ROCK" | "YOU" (rest) (clap) Type: 1 2 3 4 | 1 2 3 4
STOMP - STOMP - CLAP - (silence) 1 - 2 - 3 - 4
Beat Types Explained
- Beat 1 (Downbeat): Strongest, first stomp, marching step
- Beat 2: Weaker, second stomp
- Beat 3: Medium strength, the clap
- Beat 4: Weakest, often silence
Measure 1: STOMP(1) - STOMP(2) - CLAP(3) - silence(4) Measure 2: STOMP(1) - STOMP(2) - CLAP(3) - silence(4) Measure 3: STOMP(1) - STOMP(2) - CLAP(3) - silence(4)
Genre Emphasis
- Rock/Pop: Emphasis on beats 2 and 4
- Classical/Folk: Emphasis on beats 1 and 3
- Reggae: Off-beat emphasis (skank)
Output of Beat Timings:
Beat Type | Time (seconds)
1 | 0.0
2 | 0.5
3 | 1.0
4 | 1.5
1 | 2.0
2 | 2.5
2. Chords - Musical Building Blocks
A chord is when you play multiple notes at the same time.
- Single note = one voice
- Chord = choir
The Musical Alphabet: A, B, C, D, E, F, G (then repeats)
Basic Chord Types
Major Chords: Happy, bright (e.g., C Major = C, E, G)
Minor Chords: Sad, emotional (e.g., A Minor = A, C, E)
Piano Keys: C D E F G A B C D E F G
| | | | |
C Major: C E G
G Major: G B D
"Twinkle, Twinkle, Little Star" Twinkle, twinkle = C major little star = G major How I wonder = C major what you are = G major
Chord Progression: Most songs change chords to create tension and release. "We Will Rock You" mostly stays on one chord (E minor).
Chord Inversion: Rearranging note order (same notes, different stacking)
3. Keys - The Musical Home Base
Key = Home note everything gravitates toward
We Will Rock You key = E minor
- E feels stable and complete
- Dark, serious tone (minor)
- You can hear the key by humming the final note of the song
4. Tempo - The Speed of Music
Tempo = Beats Per Minute (BPM)
"We Will Rock You" tempo = 114 BPM
- ~2 beats per second
- Moderate tempo (80–120 BPM)
- Easy for crowd participation
How All Four Features Work Together
Time: 0s 1s 2s 3s 4s 5s 6s 7s Beats: 1 2 3 4 | 1 2 3 4 | 1 2 3 4 | 1 2 3 4 Pattern: STOMP STOMP CLAP - | STOMP STOMP CLAP - Chord: [---- E minor ----][---- E minor ----] Key: [------------- E minor throughout -------------] Tempo: [------------- 114 BPM steady ----------------]
Why This Combination is Powerful
- Simple beat pattern = Easy for crowds
- Single chord = Hypnotic repetition
- Minor key = Powerful emotion
- Moderate tempo = Accessible and energetic
MusicBench
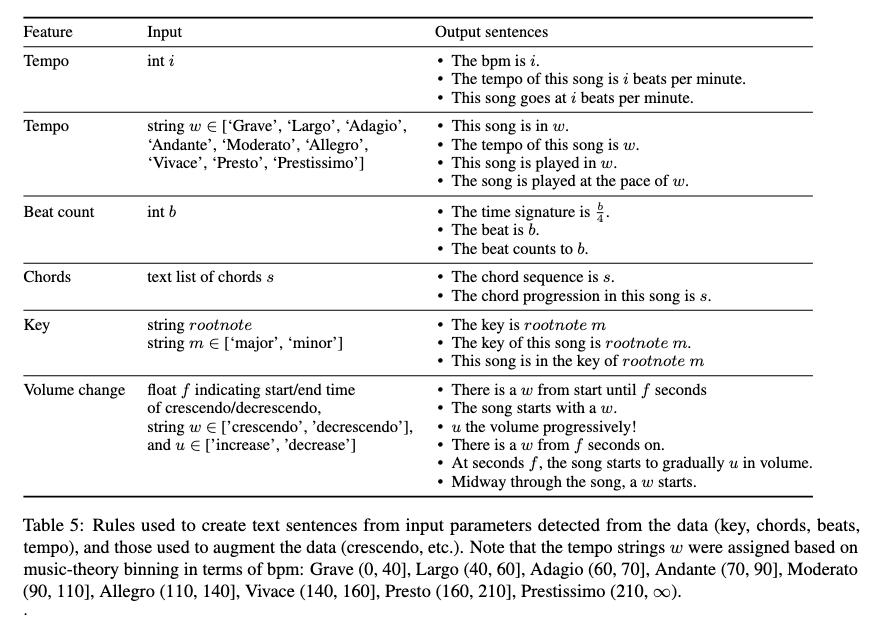
Feature Extraction
Extracts musical features from audio and converting them into text-based control information to improve music generation systems.
- Beats and downbeats
- Chords
- Keys
- Tempo
These features serve a dual purpose: they enhance text prompts with specific musical information and guide the music generation process during the reverse diffusion phase.
1. Beat and Downbeat Extraction
Uses BeatNet which outputs:
\[b \in \mathbb{R}^{(L_{beats} \times 2)}\]This mathematical notation means: \(b\) is a matrix with \(L_{beats}\) rows and 2 columns
- \(L_{beats}\) represents the total number of beats detected in the audio → Each row is one beat event.
- \(2\): Beat Type \(\in \{1, 2, 3, 4\}\) and Time
Data Structure:
- First dimension (column 1): Beat type according to meter
- Second dimension (column 2): Precise timing in seconds when each beat occurs
2. Tempo Extraction
Calculation Method: Averaging the reciprocal of time intervals between beats
Mathematical Process:
- Measure time intervals between consecutive beats
- Take the reciprocal (1/interval) to get instantaneous tempo
- Average these values across the entire piece
- Convert to BPM (beats per minute)
This approach accounts for tempo variations within a song rather than assuming constant tempo.
3. Chord Extraction
Uses Chordino which outputs:
\[c \in \mathbb{R}^{(L_{chords} \times 3)}\]This means:
- c is a matrix with \(L_{chords}\) rows and 3 columns
- \(L_{chords}\) represents the number of chord segments identified
Data Structure:
- First dimension (column 1): Chord roots
- Examples: C, D♭, F#, etc. (the fundamental note of each chord)
- Second dimension (column 2): Chord quality/type
- Examples: major, minor, maj7, dim, sus4, etc.
- Third dimension (column 3): Inversion information
- Indicates whether the chord is in root position or inverted
- Example: C major could be C-E-G (root), E-G-C (first inversion), or G-C-E (second inversion)
4. Key Extraction
Tool Used: Essentia’s - KeyExtractor algorithm
Purpose: Identifies the overall tonal center or key signature of the piece
- Examples: C major, A minor, F# major, etc.
Description Enrichment
The extracted numerical features are converted into natural language descriptions using predefined templates.
Example Control Sentences:
"The song is in the key of A minor. The tempo of this song is Adagio.
The beat counts to 4. The chord progression is Am, Cmaj7, G."
Augmentation and Music Diversification
Resulted in 11-fold increase in training data.
Why Standard Audio Augmentation Fails for Music?
Traditional Approach (e.g., Tango model): Take two audio samples → Normalize them to similar audio levels → Superimpose (layer) the audio tracks → Concatenate their text descriptions
Why This Fails for Music:
- Overlapping rhythms: Two different rhythmic patterns create chaotic, unmusical results
- Harmonic dissonance: Combining different chord progressions creates unpleasant harmonic clashes
- Conceptual mismatch: Mixing a “sad piano ballad” with an “upbeat rock song” creates conceptually incoherent training examples
The Three-Dimensional Augmentation Strategy
Instead of combining multiple audio sources, they modify individual music samples along three fundamental musical dimensions:
- Pitch Augmentation (Melodic Dimension)
- PyRubberband2, Range: ±3 semitones, Distribution: Uniform
- Technical Details:
- Semitone range rationale: Keeps instrument timbre relatively untouched
- Larger pitch shifts would cause unnatural timbre changes (e.g., making a piano sound artificially high or low)
- 3 semitones = approximately a minor third interval (musically significant but not timbre-destroying)
- Musical Impact:
- Changes the perceived pitch/key of the music
- Maintains the relative intervals between notes (preserving melody shape)
- Creates training examples in different keys from the same source material
- Speed Augmentation (Rhythmic Dimension)
- Range: ±(5% to 25%) speed change, Distribution: Uniform
- Technical Implications:
- 5-25% range represents musically meaningful tempo variations
- Slower speeds (−25%) create more relaxed, contemplative versions
- Faster speeds (+25%) create more energetic, urgent versions
- Maintains pitch relationships while altering rhythmic feel
- Musical Impact:
- Changes the perceived energy and mood
- Affects the rhythmic groove and feel
- Creates training examples spanning different tempo ranges from single sources
- Volume Augmentation (Dynamic Dimension)
- Method: Gradual volume changes (crescendo and decrescendo), Minimum volume: 0.1 to 0.5 times original amplitude (uniform distribution), Maximum volume: Kept untouched
- Technical Design:
- Gradual changes rather than sudden volume jumps (more musically natural)
- Crescendo: Gradual volume increase
- Decrescendo: Gradual volume decrease
- Amplitude range: 10-50% of original volume for minimum, preserving dynamic range
- Musical Impact:
- Simulates different recording conditions and mixing styles
- Creates variations in perceived intensity and drama
- Maintains musical expressiveness while varying dynamic profiles
More on Text Descriptions
The text descriptions are enhanced and modified in tandem with audio alterations.
Robustness Through Strategic Omission
- Method: Randomly discard 1-4 sentences describing music features
- Purpose: Enhance model robustness
Finally, we used ChatGPT to rephrase the text prompts to add variety to the text prompts.
MusicBench
Derived from MusicCaps, which contains:
- 5,521 music audio clips (10 seconds each)
- Clips include ~4-sentence English captions
- Sourced from AudioSet
- Due to missing audio, the usable dataset was reduced to 5,479 samples
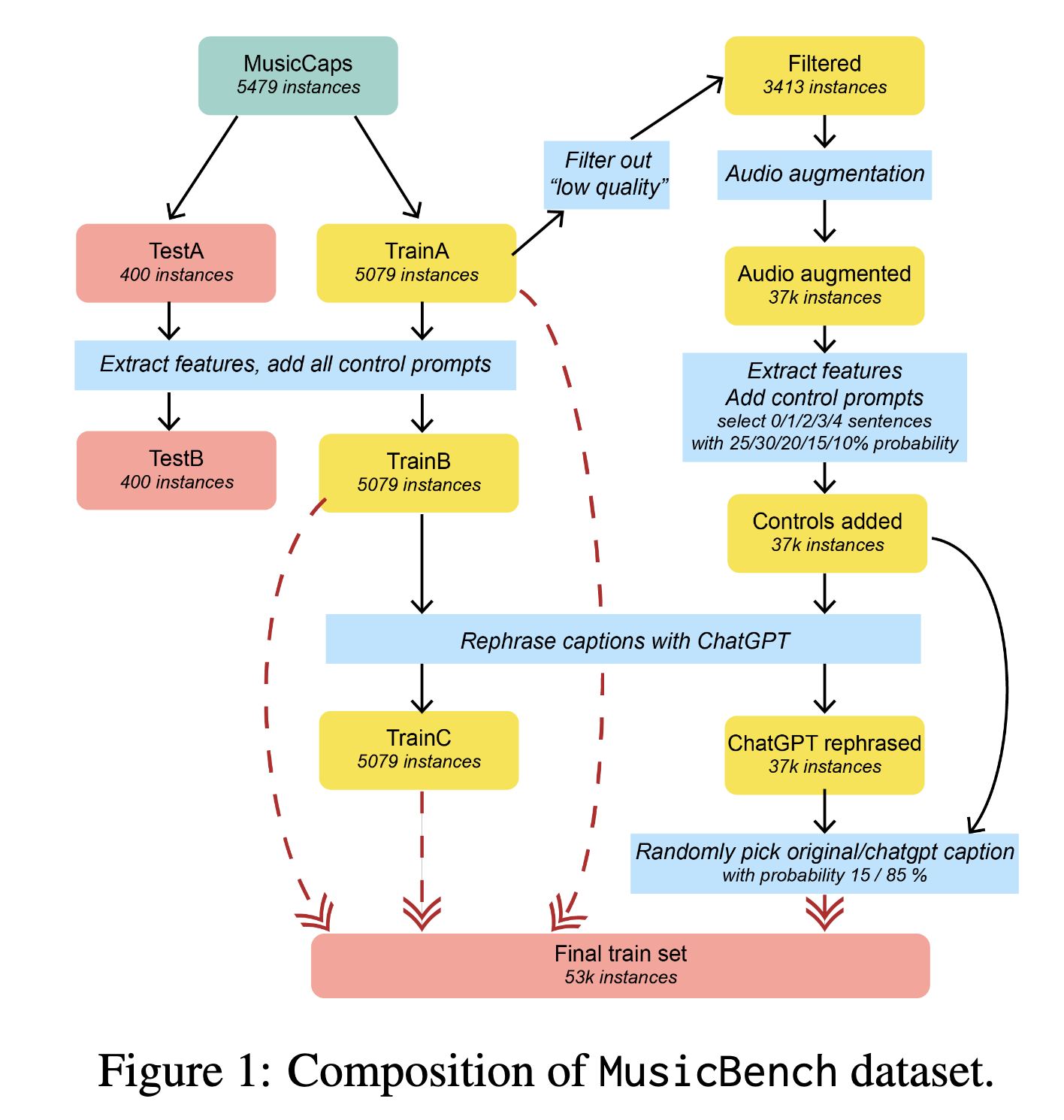
Dataset Splitting
- Initial Split:
- Divided into
TrainAandTestA
- Divided into
- Control Prompts Addition: TranB - TestB
- Appended 0–4 control sentences (describing music features) to form:
TrainBfrom TrainATestBfrom TestA
- Control prompt count probabilities: 0 → 25%, 1 → 30%, 2 → 20%, 3 → 15%, 4 → 10%
- Appended 0–4 control sentences (describing music features) to form:
- Paraphrasing (Text Robustness):
TrainCcreated by paraphrasing TrainB captions using ChatGPT- Later, all captions (original & augmented) were also paraphrased using ChatGPT
- Final training prompts use 85% paraphrased / 15% original
Data Filtering (Quality Control)
Low-quality samples filtered out using keyword filter:
- Removed any sample whose caption contains: “quality” (often refers to “poor quality”) and “low fidelity”.
- Remaining high-quality subset: 3,413 samples
Audio Augmentation (Total ~37k samples):
- Each high-quality sample augmented into 11 variants:
- Pitch shifts (6 total): ±1, ±2, ±3 semitones (excl. 0)
- Tempo alterations (4 total)
- Volume alteration (1 total)
- These augmented samples form a dataset of ~37,543 samples
Final Training Set Construction
- Final set created by combining:
- TrainA + TrainB + TrainC
- All augmented audio samples (with paraphrased and original captions)
- Resulting in a total of 52,768 samples → This final training set is called MusicBench
Test Set Details
- TestA/TestB contain:
- 200 low-quality samples
- 200 high-quality samples
- Purpose: Designed to be challenging for evaluating controllability of the Mustango model
Mustango
Mustango is a text-to-music generation model composed of two main components:
- Latent Diffusion Model (LDM)
- MuNet (Music-informed UNet Denoiser)
We have a latent audio representation — basically, a compressed version of music (\(z_0\)) created using a VAE (a type of encoder).
The model corrupts this clean music into random noise step by step (forward process), and then learns to reverse that and rebuild the music from noise — step by step — using a smart denoiser.
Latent Diffusion Model (LDM)
Goal is to Reduce computation while retaining expressivity by operating in a compressed latent space instead of raw audio.
- VAE (Variational Autoencoder):
- Encodes raw waveform to latent representation \(z_0\)
- Pretrained VAE from AudioLDM is used
- Diffusion Process:
-
Forward: Corrupts \(z_0\) into noise \(z_n \sim \mathcal{N}(0, I)\) using Gaussian schedule
\[q(z_n | z_{n-1}) = \mathcal{N}(\sqrt{1 - \beta_n} z_{n-1}, \beta_n I)\] -
Reverse: Reconstructs \(z_0\) from \(z_n\) using MuNet (denoiser) conditioned on music and text
-
Objective
Train the denoiser \(\hat{\epsilon}_\theta(z_n, C)\) to estimate noise via a noise prediction loss:
\[\mathcal{L}_{\text{LDM}} = \sum_{n=1}^N \gamma_n \mathbb{E}_{\epsilon_n, z_0} \left[ \| \epsilon_n - \hat{\epsilon}_\theta^{(n)}(z_n, C) \|^2 \right]\]MuNet
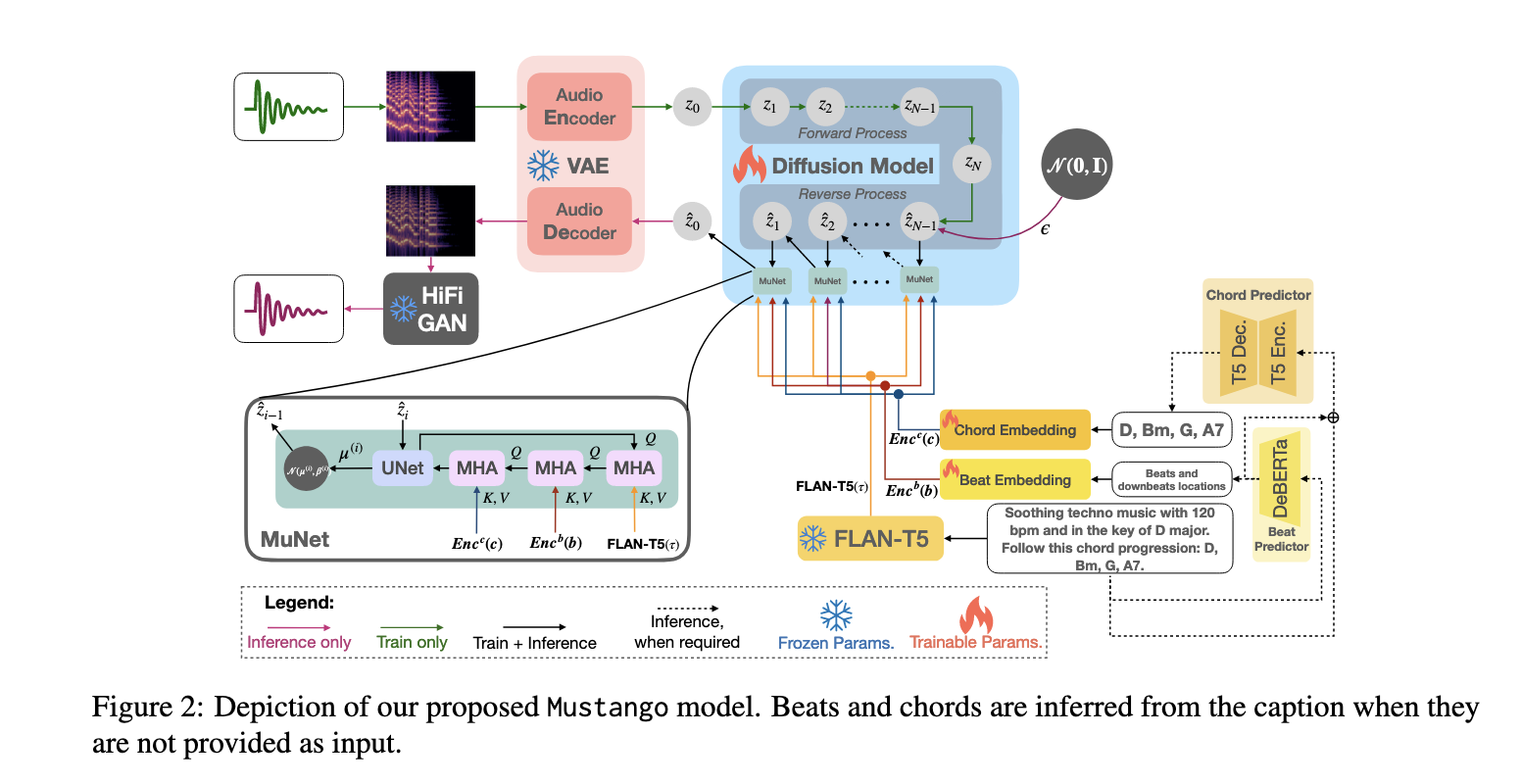
Acts as the core denoiser in reverse diffusion. It’s designed to:
- Integrate music-domain knowledge
-
Accept joint conditions:
\[C := \{\tau \text{ (text)}, b \text{ (beats)}, c \text{ (chords)}\}\]
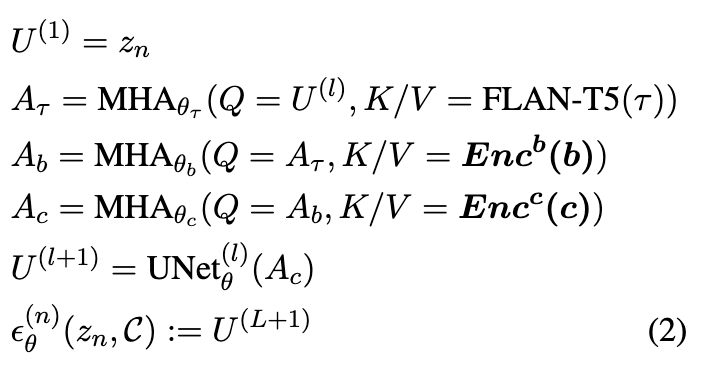
- MHA is the multi-headed attention block for the cross attentions, where Q, K, and V are query, key, and value, respectively
- FLAN-T5 is the text encoder model adopted from Tango.
- Cross-attention is applied to the beat first, as a consistent rhythm is fundamental basis for the generated music.
- MuNet consists of UNet
- Total L downsampling, middle, and upsampling blocks—and multiple conditioning cross-attention blocks.
- Both \(Enc^b\) and \(Enc^c\) leverage SOTA Fundamental Music Embedding (FME)
- Beat Encoder \(Enc^b\):
- One-hot beat type: \(\text{OH}_b(b[:, 0])\)
- Music Positional Encoding on beat time: \(\text{MPE}(b[:, 1])\)
- Combined and passed through linear projection \(W_b\)
- Chord Encoder \(Enc^c\):
- \(\text{FME}(c[:,0])\): Fundamental Music Embedding of chord root
- \(\text{OH}_t(c[:,1])\): One-hot chord type
- \(\text{OH}_i(c[:,2])\): One-hot chord inversion
- \(\text{MPE}(c[:,3])\): Positional encoding of chord timing
-
Combined then projected: \(W_c\)
\[\text{Enc}^c(c) = W_c(\text{FME}(c[:,0]) \oplus \text{OH}_t(c[:,1]) \oplus \text{OH}_i(c[:,2]) \oplus \text{MPE}(c[:,3]))\]
Reverse Diffusion Process
The reverse diffusion process reconstructs the latent audio prior \(z_0\) from pure noise \(z_N \sim \mathcal{N}(0, I)\), step-by-step, using a parametrized denoiser \(\hat{\epsilon}_\theta^{(n)}(z_n, C)\)
- Reverse Transition Distribution
At each step n, the model samples \(z_{n-1}\) from a Gaussian with:
- Mean \(\mu_\theta^{(n)}\)
- Variance \(\tilde{\beta}_n\)
- Mean for Reverse Step
Where:
- \[\alpha_n = 1 - \beta_n\]
- \[\bar{\alpha}_n = \prod_{i=1}^n \alpha_i\]
- \(\hat{\epsilon}_\theta^{(n)}\): predicted noise at step n - Predicted by the model
- This formula adjusts \(z_n\) by subtracting estimated noise and rescales it to predict \(z_{n-1}\)
- Variance of Reverse Step
- This scales the forward diffusion variance \(\beta_n\) into an appropriate reverse-time variance.
- Diffusion Coefficients
- \(\alpha_n\) controls how much signal is preserved at each step.
- \(\bar{\alpha}_n\) is the cumulative product of all previous \(\alpha\)’s and is used in rescaling.
Training Details
Authors used three types of input dropout during training:
- Dropout #1 – Drop everything (5% chance)
- The model sees no text, no beat, and no chord input.
- Why? So it learns to generate music even with zero guidance (like unconditional generation).
- Dropout #2 – Drop one input at a time (5% chance)
- It might drop just text, or just beats, or just chords.
- Helps the model handle incomplete input (e.g., caption but no beat info).
- Dropout #3 – Mask parts of a prompt
-
The longer the prompt, the more likely it is to be partially masked.
\[\text{Mask chance} = \min\left(100, \frac{10N}{M}\right)\%\]where:
- N = number of sentences in the current prompt
- M = average sentences across prompts
- Then, remove 20–50% of sentences randomly
- This teaches the model to deal with short or incomplete captions.
-
Hardware
- Training used 4× Tesla V100 GPUs and 8× RTX 8000s.
- Took 5–10 days
- Effective batch size: 32
Inference
During training, the model is given the actual (ground-truth) beats and chords.
But during inference (real-world use), it must predict those from just the text description.
Given only a text caption like:
“Soothing techno music with 120 bpm in the key of D major.”
The model must automatically figure out:
- Where the beats are (when each beat happens)
- What the chords are (and when they change)
To do this, Mustango uses two separate pre-trained transformer models:
1. Beat Predictor — Using DeBERTa Large
- Input: Text caption
- Output:
- Beat Count (1 to 4): The beat count (meter) of corresponding music
- Predicted using classification on the first token (4-class classification)
- Beat Timings (the rhythm): The sequence of interval duration between the beats (their timing)
- Predicted as float values from the next tokens (durations between beats)
- Beat Count (1 to 4): The beat count (meter) of corresponding music
Example: Suppose the model predicts:
- Beat Count: 2
- Intervals: t1, t2, t3, t4, …
Then the beat positions will be:
- Beat 1 at
t1 - Beat 2 at
t1 + t2 - Beat 1 again at
t1 + t2 + t3 - Beat 2 again at
t1 + t2 + t3 + t4 - And so on…
(Repeated in alternating fashion for 10 seconds)
2. Chord Predictor — Using FLAN-T5 Large
Predict the chords used in the music, and when each chord happens.
- Input:
- The text caption
-
Verbalized beat sequence from DeBERTa:
Timestamps: t1, t1 + t2, t1 + t2 + t3 . . . , Max Beat: 2
- Output:
- Chord progression over time in natural language
-
For example:
“Am at 1.11; E at 4.14; C#maj7 at 7.18”
This is a sequence-to-sequence generation task, where the model outputs something that looks like music sheet annotations.
- Any chords predicted after 10 seconds are ignored (since all music samples are only 10 seconds long)
How Good Are the Beat & Chord Predictors?
During inference, Mustango predicts beats & chords from text. But do these predicted features work well?
- When Control Sentences Are Present (TestB), Predictors do very well: 94.5% accuracy
- When Control Sentences Are Missing (TestA): Performance dips, but still better than Tango
- This means the predictors don’t hurt Mustango’s quality when control is missing
Final Output
Now you have:
- Beat sequence: when each beat hits
- Chord sequence: when chords start and change
These are passed into the MuNet denoiser, and the final music is generated using reverse diffusion.
Classifier-Free Guidance at Inference
\[\hat{\epsilon}_\theta^{(n)}(z_n, C) = w \cdot \epsilon_\theta^{(n)}(z_n, C) + (1 - w) \cdot \epsilon_\theta^{(n)}(z_n)\]- Purpose: Improves generation quality and controllability
- Explanation:
- The model is trained to predict noise both with and without conditions C
- At inference, both versions are interpolated using a guidance scale ww
- \(w > 1\): more faithful to the condition
- \(w = 0\): unconditional generation
- \(w = 1\): default, no guidance
Experiments
Questions explored:
- How good is the music quality produced by Mustango?
- Is Mustango better than other models like Tango, MusicGen, AudioLDM2?
- Can Mustango follow control instructions well (like beat, chord, key)?
- Is their dataset (MusicBench) strong enough to train a model from scratch?
Models Compared
Mustango Variants:
| Model Name | Description |
|---|---|
| Tango on MusicCaps | Simple baseline, no MuNet, small dataset |
| Tango on MusicBench | Same architecture, better data |
| Mustango on MusicBench | Adds MuNet + good data |
| Pretrained Tango → AudioCaps → MusicBench | Transfer learning version |
| Pretrained Mustango → MusicBench | Strongest variant (MuNet + pretrained) |
Other State-of-the-Art Models:
| Model | Notes |
|---|---|
| MusicGen (small, medium) | Text-to-music model |
| AudioLDM2 (music version) | Text-to-audio model trained on music |
Training & Evaluation Dataset
- All models were trained using the AdamW optimizer with a learning rate of 4.5e−5
- The beat and chord predictors were trained separately
- Because some models already saw MusicCaps during pretraining, they created a new fair test set called FMACaps (1,000 music clips from Free Music Archive with AI-generated captions)
Inference Setup
- All models generated 10-second audio clips
- Used 200 diffusion steps
- Classifier-free guidance scale = 3
-
Inference times on V100 GPU:
Model Time Tango 34 sec MusicGen-M 51 sec Mustango 76 sec
Objective Evaluation
How Did They Measure Quality?
They used 2 types of metrics:
Audio Quality Metrics
| Metric | What it tells us |
|---|---|
| FD (Fréchet Distance) | Statistical similarity to real music |
| FAD (Fréchet Audio Distance) | Human-perception-inspired metric |
| KL (Kullback-Leibler) | Divergence between feature distributions |
Controllability Metrics
Measured how well the generated music follows the prompt (especially for beats, chords, tempo, key):
| Metric | Meaning |
|---|---|
| Tempo Bin (TB) | Tempo (bpm) falls in correct bin |
| TBT | Tempo within bin or neighbor bin |
| CK / CKD | Correct key (exact or equivalent) |
| PCM / ECM / CMO / CMOT | Chord match (with various leniencies) |
| BM | Correct beat count |
Objective Results
Audio Quality Findings:
- Mustango (even when trained from scratch) performed as well or better than large pretrained models
- Mustango had the best FAD, which means better musicality
- The augmentation strategy (MusicBench) really works — it’s a solid alternative to large-scale pretraining
Controllability:
| Control Type | Who won |
|---|---|
| Tempo | MusicGen slightly better |
| Beats | Similar across all models |
| Key | Mustango (trained on MusicBench) best |
| Chords | Mustango wins by a large margin (especially on FMACaps) |
- Mustango excels in Key and Chord control, which are musically important.
Subjective Evaluation
Two Groups Evaluated:
- General audience — 48 people in Round 1, 17 in Round 2
- Experts — 4 trained musicians per round
They listened to samples and rated:
| Metric Name | Meaning |
|---|---|
| AQ | Audio quality |
| REL | Relevance to caption |
| OMQ | Overall musical quality |
| RC | Rhythm consistency |
| HC | Harmony and consonance |
| MCM | Musical Chord Match |
| MTM | Musical Tempo Match |
All ratings used a 7-point scale.
Subjective Results
Round 1:
- Mustango from scratch had the best ratings overall
- Experts confirmed: Mustango had the best chord match (MCM)
- Conclusion: MusicBench works, MuNet helps, Mustango is very controllable
Round 2:
- Mustango beat MusicGen and AudioLDM2 in REL (relevance to text)
- Similar performance in OMQ, HC, MTM
- MusicGen won in RC (rhythm) — slightly better rhythm matching
- Mustango won in Chord Matching (MCM)
More
Is Pretraining Mustango Necessary?
- What they tried:
- Used a Tango model that was pre-trained on 1.2 million audio-text pairs (from AudioCaps etc.) and Then fine-tuned it on Mustango’s data
- What they found:
- It didn’t help Mustango generate better music because the pretraining was on general audio, not music specifically.
- However: It might help for music + environmental sounds, like: “Jazz with thunder in the background”
How well does Mustango really do?
- Strengths:
- Great controllability — far better than previous models
- Very good music quality, even though: It was trained only on a public small-ish dataset and Competing models (like MusicGen) used huge private datasets
- Still, other models have some advantages:
- MusicGen produces: Higher audio quality in some cases and Longer musical structure (beyond 10 seconds)
Limitations:
- Model works mainly on Western music styles — control info like “chord” and “key” might not apply to Indian or Chinese music
- Can only generate 10 seconds of music due to compute limits
- Not yet optimized for long-form pieces (verse-chorus etc.)