MIMI
Streaming Capabilities of Mimi (Kyutai’s Moshi Audio Tokenizer)
Real-Time Streaming Support in Mimi
Mimi is explicitly designed as a streaming neural audio codec with impressive real-time capabilities:
- Frame Processing: Processes incoming audio in small frames (≈80ms each)
- Token Rate: Produces discrete audio tokens at 12.5 Hz in real-time
- Latency: Only 80ms algorithmic latency (the frame size)
- Causal Architecture: Fully causal - doesn’t look ahead, encodes sequentially without delay
How It Works in Practice
You can feed Mimi a continuous stream of audio (bytes or waveform chunks) and it will encode on-the-fly. For example, streaming microphone input through Mimi yields a live token stream representing the audio.
Key Achievement: Mimi compresses 24 kHz speech audio into low-bitrate tokens (1.1 kbps) on the fly, outperforming earlier non-streaming codecs at higher rates.
Concurrency: Multiple Streams and KV Cache Management
State Management Requirements
Multiple audio contexts can be handled, but each stream needs its own state:
- Mimi uses Transformers in its encoder/decoder
- Maintains memory of past frames (analogous to KV cache)
- Allows streaming without reprocessing entire history
- No built-in session separator - implementers must manage this manually
Concurrent Stream Approaches
For multiple streams concurrently (e.g., different calls or users):
- Separate Instances: Instantiate separate Mimi model objects
- State Management: Reset/manage cached state between streams
- Independent Contexts: Ensure separate KV caches or session state
Real-World Performance Examples
Moshi Framework: Already handles two streams simultaneously (user incoming + Moshi outgoing) using separate channels.
GPU Batching: Kyutai’s demo achieved 384 concurrent user streams on a single H100 GPU for real-time STT by processing in parallel.
Hardware Considerations
- GPU: Batch multiple streams with separate input buffers
- CPU: Run multiple streams in threads/processes
- Main Limitation: Computational resources - each stream scales linearly with CPU load
Summary: Mimi’s streaming mode supports multiple streams, but you must manage each stream’s state separately to avoid interference.
Performance Considerations: CPU vs GPU
GPU Performance (Recommended)
Mimi’s model (hundreds of millions of parameters) was optimized for modern GPUs:
- NVIDIA L4: Achieves ~160–200ms end-to-end latency
- Processing Requirements: 12.5 forward passes per second of audio (12.5 Hz token rate)
- Apple M3 MacBook Pro: Can run in real-time with Metal/ANE acceleration
CPU Challenges and Solutions
Standard CPU Limitations:
- Typical x86 CPU cannot achieve real-time 24 kHz streaming with full-precision model
- Requires heavy optimization or scaling down
Optimization Strategies:
- Quantized Models: Kyutai released quantized versions for CPU inference
- moshi_mlx Package: Supports 8-bit and 4-bit quantization for macOS
- 4-bit Quantization (
-q 4flag): Greatly reduces compute/memory load
Performance Recommendations
| Hardware | Performance | Notes |
|---|---|---|
| GPU | ✅ Best streaming performance | Low latencies (few hundred ms) |
| Apple Silicon | ✅ Real-time capable | With proper optimization |
| Standard CPU | ⚠️ Higher latency | Needs quantization/optimization |
For CPU Deployment: Plan for performance tuning (quantization, multi-threading) and consider that multiple concurrent streams will further tax the processor.
Hugging Face Transformers Support for Streaming
Current Integration Status
Hugging Face’s Transformers library provides basic integration (MimiModel) but native streaming support is limited:
✅ What Works:
- Encode full audio tensor into tokens
- Decode tokens back to audio
- Basic model card usage examples
❌ What’s Missing:
- Out-of-the-box “streaming mode”
- Automatic state caching for incremental audio
- Real-time optimizations
Official Recommendation
Hugging Face explicitly recommends using Kyutai’s original codebase for real-time streaming inference.
The Transformers integration is described as an “intermediate” solution for:
- Experimentation
- Non-real-time use
- Prototyping
Manual Implementation Requirements
To stream audio through Mimi using PyTorch/Transformers, you need extra logic:
- Chunk Processing: Manually process audio in chunks
- State Management: Carry over model’s internal state between calls
- KV Cache Handling: Manage “past” states manually
- Session Management: Maintain separate audio buffers per session
Alternative Solutions
For real-time applications, consider:
- Kyutai’s streaming server: Proper state handling built-in
- Rust bindings (
rustymimi): Optimized implementation - Custom Python loop: Manual streaming implementation
Bottom Line: Extra logic is required for true streaming behavior via Transformers backend. Use the original implementation for production real-time applications.
Kyutai’s Moshi-Mimi Streaming Audio Tokenizer – Technical Overview
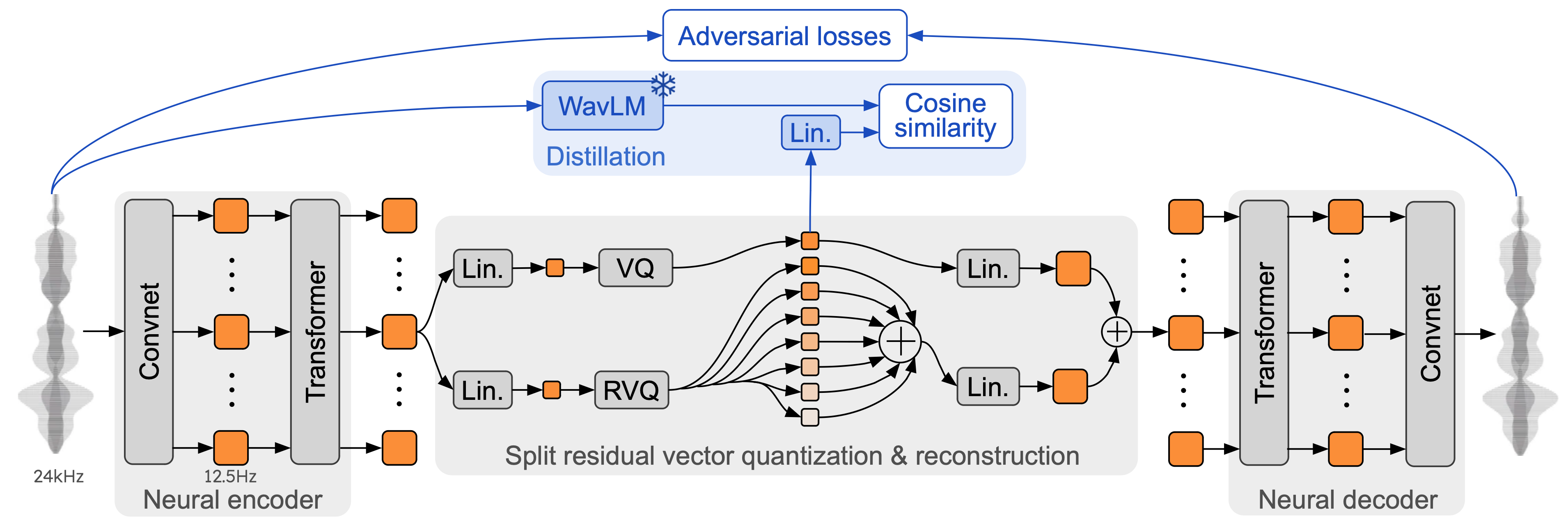
Figure: Architecture of the Mimi neural audio codec used in Moshi. Mimi’s encoder (left) and decoder (right) each combine convolutional layers (“Convnet”) with Transformers, enabling a fully causal, streaming design (12.5 Hz frames ≈ 80 ms). A split residual vector quantization (RVQ) bottleneck produces semantic tokens (via distillation from a WavLM teacher, top) and acoustic tokens, jointly capturing high-level content and audio details. Adversarial loss training further improves fidelity.
Implementations and Language Bindings
Kyutai’s open-source Moshi repository provides three parallel implementations of the Moshi/Mimi inference stack:
-
Python (PyTorch) – A reference implementation under the
moshi/directory. This uses PyTorch for both the Mimi audio codec and the Moshi language model. It currently requires high-precision weights (bf16/fp16) and a GPU with large VRAM (≈24 GB for 7B model) since quantization is not yet supported in the PyTorch version. This Python API is available via PyPI (pip install moshi). It exposes Mimi and Moshi as standard PyTorchnn.Modulemodels and supports streaming (see below). This version is useful for research or finetuning, but due to lack of 4/8-bit quantization it demands substantial GPU memory. -
Python (MLX for Apple Silicon) – An optimized implementation for macOS M-series chips, in
moshi_mlx/. It leverages Apple’s Metal Performance Shaders (via the MLX library) to run Moshi on the GPU/ANE of Apple Silicon (M1/M2/M3). Under the hood, this client uses Kyutai’s Rust Mimi library (via therustymimiPython binding) for the audio codec, and an MLX-based backend for the 7B language model. It supports int4 and int8 quantized checkpoints for efficiency. For example, users can install and run it with:pip install moshi_mlxand thenpython -m moshi_mlx.local_web -q 4(the-qflag selects 4-bit quantization on Apple Silicon). This allows Moshi to run locally on a MacBook (no internet) with acceptable speed. The MLX version has been tested on a MacBook Pro M3 and supports int4, int8, and bf16 model weights, making it ideal for Apple devices. (Note:moshi_mlxwill only install on macOS; it is not compatible with Linux/Windows without an M-series chip.) -
Rust (C++/Candle) – A high-performance Rust implementation (in the
rust/directory) intended for production use. It uses the Candle ML framework (developed by Moshi’s authors) for running the models, and can target both GPU (CUDA or Metal) and CPU. The Rust codebase includes the Mimi codec and the Moshi transformer, plus a multi-threaded streaming server. Notably, Python bindings for the Rust Mimi codec are provided via therustymimipackage.rustymimican be installed from PyPI (pip install rustymimi) and gives access to Mimi’s encode/decode functions in Python, but powered by the optimized Rust backend. In fact, the MLX client above usesrustymimito handle audio tokens. The Rust implementation supports quantized models (int8, bf16) for Moshi. It’s designed for real-time streaming in native applications – for example, Kyutai provides a Rust binarymoshi-backendthat serves a low-latency voice chat API. Developers can compile it with CUDA or Metal support for GPU acceleration. This is the backend that powers the official Moshi demo and can be integrated into other languages (e.g. via FFI).
In addition, bindings and integrations are emerging for other environments:
-
Hugging Face Transformers Integration – Mimi has been integrated into the Hugging Face Transformers library as
MimiModel(and a corresponding feature extractor). This allows Mimi to be used like any other transformer model for offline encoding/decoding of audio (e.g. encoding audio into tokens or reconstructing audio from tokens). However, the HF integration is primarily batch/offline – it does not natively expose Mimi’s streaming context. It’s useful for evaluation or non-streaming pipelines. -
Mobile/Swift – Kyutai provides an experimental Swift/IOS implementation of Moshi and Mimi (the
moshi-swiftrepo) for on-device use. It uses Swift wrappers around MLX (“MLX Swift”) to run the fully streaming Mimi codec and Moshi model on iOS devices. The goal is to enable real-time voice AI on iPhones/iPads. An iOS demo app is included (proof-of-concept). This demonstrates the portability of the core model – leveraging Apple’s neural engine and Metal via Swift – though it’s still experimental.
Table 1 summarizes the key implementations and their capabilities:
| Implementation | Language / Platform | Backend | Streaming Support | Quantization Support | Notes |
|---|---|---|---|---|---|
| PyTorch (moshi) | Python (>=3.10) | PyTorch (GPU) | Yes – via context mgr. | No quant (bf16 only) | Reference code; requires high VRAM. |
| Apple MLX (moshi_mlx) | Python on macOS (M1/M2/M3) | Apple ML Compute (Metal/ANE) + Rust Mimi | Yes – real-time optimized | Int4, Int8, bf16 | Optimized for Apple Silicon; uses rustymimi. |
| Rust/Candle | Rust (with Python API rustymimi) |
Candle ML (CPU/GPU) | Yes – production-grade | Int8, bf16 (Int4 not in Candle) | Fast native server; multi-threaded CPU support. |
| HF Transformers | Python | PyTorch (or ONNX) | Partial (offline encode/decode) | bf16 (no int4/8 in Transformers) | Easy integration for non-streaming tasks. |
| Swift (iOS) | Swift (iOS 17+) | MLX Swift (Metal/ANE) | Yes – on-device | Int4, Int8 (via MLX) | Experimental mobile support (proof-of-concept). |
Table 1: Moshi/Mimi available implementations and bindings, with supported features.
Real-Time Streaming Design
Moshi-Mimi is built for real-time, streaming operation. Both the Mimi codec and the Moshi 7B transformer generate outputs incrementally, rather than waiting for an entire utterance. Several mechanisms enable this:
-
Causal, stateful models: Mimi’s internal models (the encoder and decoder transformers in the codec, and the Moshi transformer) are trained to be causal and support incremental computation. Mimi’s encoder and decoder operate with a frame size of 80 ms, meaning after ~80 ms of audio input, Mimi produces the first token (which corresponds to 80 ms of decoded audio). The Mimi decoder can then regenerate that 80 ms chunk of waveform immediately. Importantly, Mimi’s Transformers use a limited-context self-attention (up to 250 frames ≈ 20 s of context) to ensure they don’t require unbounded future context. This allows truly streaming encode/decode with a manageable memory footprint. The Moshi language model likewise generates one token (which represents one audio frame’s worth of content) at a time, conditioned on past tokens.
-
Streaming state (KV-cache) management: To avoid re-computation from scratch at each step, the implementations maintain internal state (key/value caches) across time steps. In the PyTorch API, this is exposed via a context manager. For example, to stream-decode audio tokens, one would use:
with mimi.streaming(batch_size=1): for t in range(num_frames): audio_chunk = mimi.decode(tokens[:, :, t:t+1]) output_audio.append(audio_chunk)Here
mimi.streaming(...)creates a streaming context that preserves the decoder’s state (e.g. Transformer KV cache or convolution states) across successivedecodecalls. Without this, decoding frame-by-frame would produce artifacts at the boundaries. In a GitHub Q&A, the developers confirmed that forgetting to use the streaming context led to noisy outputs, which was resolved by wrapping the encode/decode loop inwith mimi.streaming(...). Under the hood, this context likely initializes or resets internal caches and ensures past frames inform the generation of the next frame. The Rust implementation similarly manages state through persistent decoder objects – for instance, one can feed successive frames into the same Mimi decoder instance, which accumulates state internally (therustymimiAPI provides stateful calls toencode/decodeas well). This design is analogous to how large language models stream text by carrying a KV cache of past attention keys/values. -
Concurrent dual streams (full-duplex audio): A hallmark of Moshi is its ability to handle two audio streams simultaneously – the user’s audio (incoming microphone speech) and Moshi’s own audio (the AI’s spoken response). The system is essentially full-duplex: Moshi can listen while talking. This is implemented by treating the two audio token streams as separate channels in the model input. At each time step (each 80 ms frame), Mimi encodes the user’s recent audio into a token, while the Moshi model generates the next token for its own speech. These tokens are fed into the Helium 7B transformer in a multi-stream format, effectively “stacking” or concatenating the user stream and Moshi’s stream tokens for the same timestep. The Moshi model was trained on this multi-stream setup, allowing it to learn to handle overlap, interruptions, and turn-taking without explicit segmentation. In practice, the inference server interleaves the processes: as audio input frames arrive, Mimi encodes them and appends user tokens to the context; concurrently, the model predicts its next token and Mimi’s decoder produces audio output. The concurrency is handled by the streaming server/client – e.g. the Python Gradio-based server uses an audio worklet to continuously send microphone frames and play back output audio in real-time. The design ensures minimal coupling between streams aside from time alignment. As Kyutai describes, “the model handles two audio streams concurrently, enabling it to listen and speak simultaneously.”. The official web UI client even implements echo cancellation and adaptive lag control (skipping output frames if needed to catch up) to maintain smooth real-time dialogue.
-
Threading and asynchronous I/O: Under the hood, the implementations use multi-threading or async pipelines to achieve low latency. For example, the Rust server spawns separate tasks for audio input processing, model inference, and audio output. The Python server likely uses non-blocking queues or async loops to feed audio frames into Mimi while the transformer is generating. The result is a tightly pipelined system: Moshi’s end-to-end latency is ~160–200 ms, meaning it takes only about 0.2 seconds from the user speaking to Moshi replying. This includes Mimi encoding/decoding and one inference step of the 7B model – an impressive feat made possible by streaming states and parallel stream handling.
Concurrent stream handling is further facilitated by the multi-stream token format introduced in Moshi’s architecture. Essentially, at each time index, the model expects a pair of tokens: one representing user audio (or a padding token if the user is silent) and one for Moshi’s own audio (or a special silence token if Moshi isn’t speaking). This parallel token stream approach lets the model naturally handle overlaps. There is no explicit lock-step turn-taking; both streams advance continuously, and the model’s next output can be conditioned on the user’s current input. This design was a key innovation to achieve full-duplex conversation.
In summary, real-time streaming is enabled by Mimi’s 80 ms frame discretization, context-preserving decode/encode calls, and a multi-stream input paradigm. Each implementation (Python, Rust, MLX) provides mechanisms to maintain state across calls. For developers, this means you can encode or decode chunk-by-chunk in a loop (using the provided context managers or stateful APIs), and the output will be as if processed by one continuous model on the whole sequence. Moshi’s ability to stream concurrently in two channels is relatively unique, and the codebase explicitly supports it (the open-source demo runs a local server where the user’s microphone stream and the model’s output stream are handled together in real time).
Performance Benchmarks Across Hardware
One of Moshi’s claims to fame is achieving real-time performance on modest hardware, thanks to optimized implementations and quantization. Here we summarize known performance benchmarks and hardware requirements:
-
GPU (NVIDIA CUDA): On a typical modern GPU, Moshi runs comfortably in real-time. The authors report a theoretical 160 ms and practical ~200 ms latency on an NVIDIA L4 GPU for one round of dialogue (L4 is a mid-range data center GPU). This sub-0.2s latency indicates that the model processes audio faster than real time (generating 1 second of speech in 0.2s). High-end GPUs (A100, RTX 4090, etc.) can only improve throughput. The main constraint is memory: the 7.7B model in bf16 requires ~16 GB of GPU memory. Running the non-quantized model on, say, a 16 GB GPU (like an RTX 3080) will be near the limit but possible. With 8-bit quantization, memory drops to ~8 GB, which fits on consumer GPUs like RTX 3070, etc., and with 4-bit it’s ~4 GB. In the open-source release, Kyutai provided 8-bit model checkpoints for CUDA (labeled “experimental”) which reduce VRAM usage by half. They did not release a 4-bit for CUDA (likely because 4-bit was targeted to Apple), but third-party quantization could achieve it if needed. In practice, using the int8 model, GPUs with ~8 GB VRAM can run Moshi. In terms of speed, those GPUs should still achieve or approach real-time, especially if using optimized kernels (the Rust/Candle backend supports FlashAttention and other speedups).
-
CPU (x86): The Moshi authors included CPU support, but running a 7B transformer in real time on CPUs is extremely challenging. The Rust/Candle backend can use multi-threading (via Rayon) to utilize many CPU cores. However, an issue comment from the developers notes that “Moshi needs to be real time and this would be very tricky on CPU-only even with 120 cores”. This implies that, as of now, pure CPU inference is not practical for real-time dialogue, unless you have a massive server-grade CPU. For offline or slower-than-real-time processing, one could run the int8 model on CPU. The Rust implementation’s CPU path and the fact that it’s optimized in C++ could make it perhaps 5–10× slower than real time on a high-end desktop CPU (rough estimate). The open-source emphasis has been on GPU and Apple Silicon. In summary, while a CPU backend exists (and is functional for testing), real-time use on CPU is not recommended. Moshi is designed to leverage GPU/accelerator hardware for the heavy 7B model.
-
Apple Silicon (Metal/ANE): A major selling point is that Moshi can run on Apple M-series chips without any external GPU. The MLX-based implementation offloads the 7B model to the 16-core GPU (and potentially the Neural Engine) on M1/M2/M3 chips, and uses 4-bit or 8-bit weights to fit in memory. Community members have successfully run Moshi on a MacBook Pro M2 Pro 16 GB using the 4-bit quantized model (Moshika-MLX-Q4) at real-time speed. Kyutai themselves tested on an M3 MacBook Pro, achieving real-time dialog processing. Apple’s Metal Performance Shaders and matrix multiplication libraries are highly optimized, so the model can achieve ~200 ms latency on these laptops as well. Scalability: The linkedIn summary of Moshi noted “a smaller variant of Moshi can run on consumer-grade hardware, such as a MacBook or a standard GPU.” In this context “smaller variant” refers to the quantized or optimized model. Indeed, int4 quantization allows a 7B model to condense to ~4 GB of memory, which easily fits in an M1 Mac’s unified memory. Users have noted that using
moshi_mlx -q4on M1/M2 will run, though occasionally one may need to retry due to some instability (likely memory pressure or ML Compute quirk). Overall, Apple Silicon can handle Moshi in real time with the provided MLX package – a notable achievement for an audio language model of this size. -
Latency and Throughput: Across the above hardware, the end-to-end latency hovers around 0.2 seconds (200 ms) for a streaming interaction, which includes the model thinking and speaking for ~80 ms of audio at a time. The 12.5 Hz token rate is a fixed property of Mimi (12.5 tokens/sec → 80 ms per token). Moshi’s design generates exactly one token per 80 ms frame. Thus, one can think of it as producing speech at 1× speed if the compute can keep up with generating 12.5 tokens/sec. The reported benchmarks indicate they have achieved slightly faster than 1× on certain hardware (which is why latency can be under 1 frame). For instance, on the L4 GPU, the model likely can generate an 80 ms audio token in ~16 ms (hence ~5× faster than real-time, giving 160 ms for 1 s of audio). On a Mac M2, it might be closer to 1× or slightly slower, but still within real-time bounds by buffering a small delay. Kyutai’s demo and tests confirm practical real-time performance on single GPUs and Apple laptops. It’s also worth noting the 7.69B model size itself: in bf16 it’s ~15–16 GB, int8 ~7.5–8 GB, int4 ~3.8–4 GB as mentioned. So memory is the primary factor in hardware choice (GPUs with <8 GB cannot run the full model unless CPU offloading or further compression is used).
To summarize: On GPUs, Moshi can achieve ~200 ms latency easily (real-time), with int8 allowing consumer GPUs to join the fray. On Apple M-series, the specialized int4/int8 build also achieves real-time on a MacBook. CPU-only runs exist but fall short of real-time by large margins. The framework is designed to be flexible with backends – it supports CUDA, Metal, and even CPU in one codebase – but not all backends can meet the real-time requirement. Kyutai’s focus has been on ensuring CUDA and Metal paths are fast and quantized for on-device use. The result is an impressive cross-platform performance profile for a model of this complexity.
Quantization and Output Quality Trade-offs
Moshi and Mimi employ quantization at two levels: (1) the audio codec tokens themselves are a compressed (quantized) representation of audio, and (2) the model weights of the Moshi transformer can be quantized (e.g. 8-bit or 4-bit) to reduce memory. Here we discuss how these quantizations affect output quality.
Mimi Codec Quality: Mimi is a lossy neural codec – it compresses 24 kHz speech to 1.1 kbps (about 95× compression). Despite this extreme compression, Mimi achieves state-of-the-art fidelity for speech. According to Kyutai, Mimi’s architecture (which combines semantic and acoustic RVQ codebooks) outperforms prior neural codecs like Facebook’s RVQGAN/Encodec, Google’s SoundStream, and SpeechTokenizer in quality. In their technical report, they rigorously evaluated Mimi’s reconstruction quality. They used both objective metrics – e.g. VisQOL (an objective acoustic similarity score) and MOSNet (a neural predictor of Mean Opinion Score) – and human listening tests (MUSHRA tests with 20 listeners). The results (reported in Table 4 of their paper) showed that Mimi (with full 8-codebook RVQ and their proposed improvements) achieved MUSHRA scores in the mid-60s, on par with or slightly better than the previous best codec (SemantiCodec ~64.8 MUSHRA). For reference, a score of 64–65 in MUSHRA indicates fair-to-good quality; the ground truth audio is 90+ and a traditional low-bitrate baseline was ~31. In other words, Mimi reconstructs speech with much higher quality and intelligibility than older 1.5 kbps methods (which often sounded robotic), and is nearly transparent in many cases. The inclusion of a “semantic token” (distilled from WavLM) helped Mimi retain word-level content (low ABX error rates) even at low bitrates, while adversarial training improved the naturalness of the audio (yielding better MOSNet and human preference).
From a subjective standpoint, Mimi’s output is very high quality for speech – most listeners would find it natural, with minor smoothing of very fine details. An independent blogger who tested Mimi wrote that “the quality, especially for speech, is impressive”, noting that the semantic+acoustic token approach “opens up new possibilities” in generation. In short, using Mimi tokens instead of raw audio does not significantly degrade the conversational experience; it preserves voice identity, emotion, and intelligibility well, while compressing audio into a manageable token stream.
Weight Quantization (4-bit & 8-bit) and Quality: Quantizing the Moshi model weights to 8-bit or 4-bit is crucial for deployment, but it can introduce modeling artifacts if not done carefully. Kyutai released 8-bit quantized checkpoints for both the PyTorch and Rust/MLX backends, and 4-bit for the MLX (Apple) backend. These were marked “experimental” for PyTorch, suggesting that quality might be slightly impacted or at least unverified. According to the team, 8-bit (int8) quantization has minimal effect on output quality – the int8 models require half the VRAM and still produce clear audio and coherent speech. In fact, most users ran the 8-bit models by default to fit GPUs or to use MLX on Mac. There haven’t been reports of major differences between bf16 and int8 in terms of the audio’s sound or the model’s word choice, which implies int8 is essentially transparent (this is expected, as int8 quantization of LLMs usually preserves perplexity and accuracy within ~1–2% of full precision).
With 4-bit (int4) quantization, there is a higher risk of quality degradation. Kyutai did provide 4-bit models for Apple, indicating they found it still usable. However, in their paper’s appendix, they delve into artifacts caused by model quantization. They specifically mention that at “low bitwidth” quantization (e.g. very low precision weights), the model can exhibit issues like “gibberish” speech output. Gibberish here means the audio is fluid but the content is nonsensical – an error likely from the language model struggling with extreme quantization noise. They note this is “very common… at low bitwidth (W2)”, presumably referring to 2-bit weights as an extreme case. For 4-bit (which is less extreme), the artifacts are milder but can still occur. The paper identifies a few typical quantization-induced artifacts:
-
Repetitive text: The model may start looping phrases or words repeatedly (e.g. “okay okay okay…”). This is characterized by flat entropy in the text token stream. Quantization can reduce the precision of the transformer enough that it falls into repetitive output. Users have indeed observed Moshi sometimes overusing filler words or repeating itself more in quantized modes (one user noted Moshika int4 tended to add extra “uh” and other stall words in output).
-
Background noise during silence: Ideally, when Moshi is not speaking, the audio tokens correspond to near-silence (just background room noise). Under heavy quantization, they observed cases where a silence “degrades” into background hiss or artifacts. Essentially the model’s audio codec tokens become noisy even though no speech is happening. This is an artifact of the model weights not precisely maintaining the delicate silence token generation.
-
General “noisy” audio: Even while speaking, the timbre or clarity of the voice can degrade slightly with quantization. The paper mentions detection of Noisy Audio artifacts by looking at entropy across codebooks. Listeners might perceive this as a slight metallic tinge or a less crisp pronunciation compared to the full precision model.
Despite these potential issues, the 4-bit models are largely intelligible and useful. The artifacts tend to grow over longer outputs – for example, a long monologue might accumulate noise or repetitive tics over time. In a dialogue setting with short replies, one might hardly notice any problem. Kyutai’s Appendix D was proactive in characterizing these artifacts to guide future improvements or dynamic quantization strategies. It’s worth noting they specifically experimented with mitigation: e.g. they tried partial quantization during training (what they call “Quantization rate 50%” in Section 5.2) and found that it improved VisQOL (objective quality) but did not notably change human-perceived quality. This indicates that moderate weight quantization doesn’t fool the ear much – a good sign for using 8-bit and 4-bit models.
In practical terms, users should expect almost no quality difference with 8-bit, and minor potential degradations with 4-bit: perhaps a slightly higher chance of repetitive words or a faint added distortion. The voice identity and overall intelligibility remain strong even in 4-bit. Memory and latency benefits, however, are significant (4-bit cuts memory in half vs 8-bit, and allows fitting on small devices). For many, that trade-off is worthwhile. Kyutai’s release of 4-bit for Mac suggests they deemed the quality acceptable for conversational use.
To illustrate the trade-off, consider Table 2 below, which compares quantization levels:
| Model Variant | Weight Precision | VRAM / Memory (7B) | Subjective Quality | Noted Artifacts |
|---|---|---|---|---|
| Full / BF16 | 16-bit (bf16/fp16) | ~16 GB GPU memory | Baseline – High fidelity, no added artifacts | (Baseline) |
| Int8 Quantized | 8-bit | ~8 GB GPU memory | Near-baseline – virtually no audible loss | None major (int8 marked experimental but widely fine) |
| Int4 Quantized | 4-bit | ~4 GB GPU or unified memory | Slightly degraded – mostly natural, but some quality drop in long outputs | Occasional repetitive words or noise in silence |
| Extreme (not released) | 2-bit (W2 in paper) | ~2 GB (theoretical) | Poor – “gibberish” likely | Frequent incoherence, artifacts |
Table 2: Quantization impact on Moshi/Mimi model size vs. output quality. (Kyutai provides models in bf16, int8, and int4; 2-bit is an experimental scenario from the paper for analysis.)
Kyutai explicitly emphasizes that “more aggressive quantization does not improve perceived quality” even if some objective scores fluctuate. They therefore stick to int8 and int4 as the lowest precisions that keep quality within acceptable range. Users who require absolute best quality should run the bf16 model (if GPU memory allows). But for most real-time deployments, int8 is a sweet spot, and int4 makes it possible on ultra-light hardware at the cost of very minor quality regressions.
It’s also important to note that the Mimi audio codec itself is discrete by design – it uses 8 codebooks of 1024 entries (effectively an 8×10-bit representation per frame). This token quantization is separate from weight quantization. Mimi’s token bitrate (1.1 kbps) was chosen to maximize quality; pushing it lower (fewer codebooks or smaller codebooks) would directly degrade audio fidelity. The current setting yields high MOS scores as discussed. Thus, the “quantized latent space” mentioned in documentation refers to these codec tokens and is a feature, not a bug – it’s how speech is compressed. In contrast, weight quantization is a deployment optimization and can be adjusted (one could run an int8 codec model vs an int4 codec model) with the above trade-offs.
Official stance: The Kyutai team is upfront that int4 is experimental but enables the “smaller variant of Moshi on consumer hardware”. They are likely continuing to refine quantization (perhaps with techniques like GPTQ or AWQ to reduce error). As of the v0.1 release, int8 is quite solid. Int4 works, with some quirks observable under certain conditions (which they categorized into repetitive text, etc.). The encouraging part is that these artifacts can often be detected and possibly mitigated – for example, one could add logic to avoid stuck repetition if entropy flatlines. Future improvements may make the int4 nearly as good as int8.
In conclusion, Mimi’s output quality is state-of-the-art for a 1 kbps codec, making it suitable for training and driving a speech LM, and quantizing Moshi to 8-bit or 4-bit has a reasonable trade-off: huge memory savings at the cost of a slight increase in artifact probability (particularly with 4-bit). The user should choose based on their hardware – if you have the capacity, use the 8-bit or full model for ultimate quality; if you need to fit in 4 GB or run on mobile, the 4-bit will still give an impressive demo of conversational AI, just keep an ear out for the occasional quirk.
Tools, Packages, and Demos Supporting Mimi Streaming
Kyutai has provided various tools and examples to help developers experiment with Moshi and Mimi in streaming mode, as well as support for the quantized models:
-
Moshi Server and Client (PyTorch) – The repository includes a reference streaming server (
moshi.server) and web client (moshi.client) for interactive use. By runningpython -m moshi.server --hf-repo <model>one can host the Moshi model and use a React/Gradio-powered web UI to chat with it locally. This server uses the PyTorch backend (hence requires a beefy GPU unless you switch to the MLX version). The web UI handles microphone input and speaker output in the browser, showcasing full-duplex voice chat. There’s also a CLI client that can connect to the server for a terminal-based interaction (though it lacks advanced features like echo cancellation). This is a great starting point to see Mimi streaming in action. -
rustymimiPython API – As mentioned,rustymimiallows you to use the Rust Mimi codec in any Python project. For example, a developer using a custom TTS system could encode audio to Mimi tokens or decode Mimi tokens to audio waveforms by simply callingrustymimi.encode(waveform)andrustymimi.decode(tokens). Because it’s backed by the optimized Rust, it’s much faster than a Python implementation.rustymimiis also a dependency ofmoshi_mlx(it installs automatically with it). This package is useful if one only cares about the audio codec aspect (say, compressing speech) or wants to plug Mimi into other pipelines. -
Moshi-MLX package – The
moshi_mlxPyPI package is essentially a tool itself. It bundles the Apple-optimized pipeline and is very easy to use: “just runpip install moshi_mlxandpython -m moshi_mlx.local_web -q 4on an Apple Silicon Mac” to launch the local web demo. Under the hood this downloads the quantized model from Hugging Face (e.g.kyutai/moshika-mlx-q4) on first run. Themoshi_mlx.local_webscript sets up a minimal Gradio interface similar to the PyTorch server, but using the MLX backend (Metal). It’s a convenient one-command demo for Mac users (even those not familiar with Python can use it). This is the path that folks like Andrej Karpathy highlighted to try Moshi on a MacBook. -
Hugging Face Model Repos – All the models (Mimi, Moshiko, Moshika in various precisions) are published on Hugging Face Hub for easy access. Notably:
kyutai/mimi(the codec alone),kyutai/moshiko-pytorch-bf16/-q8(male voice model),kyutai/moshika-mlx-q4/-q8/-bf16, etc.. These repos contain the model weights and configuration. Hugging Face’s Transformers can loadkyutai/mimidirectly for encoding/decoding as mentioned. For streaming, one would still need to manage state manually, but having the weights on HF makes it easier to fetch and version control. There is also a HF Collection for Moshi v0.1 release that groups all related repos. Developers can use the Hub to pull models for different backends as needed (for example,moshi_mlxknows to load the-mlx-q4checkpoint). -
Hibiki (speech translation) and Others – The Moshi framework has inspired related tools. Kyutai released Hibiki, a simultaneous speech-to-speech translation model built on the same multi-stream principles (it uses Mimi for audio tokens as well). While Hibiki is a separate model, it reuses Mimi; the
moshi-swiftproject explicitly mentions supporting all Moshi and Hibiki variants with the same codebase. This means tools built for Moshi/Mimi can often be extended to other tasks like speech translation. It underscores the flexibility of Mimi as a general audio tokenizer. -
Community Demos – Beyond official tools, early adopters have created their own demos. For instance, some enthusiasts in the
r/LocalLLaMAcommunity integrated Moshi’s voice chat into custom interfaces, or built voice assistants that use Moshi for the speech part and another brain for general conversation. The existence of an easy API (likemoshi.clientandmoshi.server) facilitates such projects. While not “official”, they are worth noting as they often end up on GitHub or Hugging Face Spaces. For example, one might find a Space where Moshi is running and can be tried in-browser without setup. The official demo was at moshi.chat (which was Kyutai’s hosted instance); if that is unavailable, the local server is the way to go.
In summary, developers interested in Mimi streaming or using quantized Moshi have a rich set of tools: from straightforward pip packages (moshi, moshi_mlx, rustymimi) to full examples of servers and clients. The official recommendation is to use the Rust or MLX backends for performance and quantization, and to use the provided context manager or streaming APIs to ensure real-time operation. Kyutai has prioritized making the tech accessible: one can get a voice conversation running on a laptop with a single pip install, which is quite remarkable for a model of this kind.
Finally, all releases are under a permissive license (CC-BY for the model weights, and MIT/Apache for code), so the community is encouraged to build on Moshi-Mimi. Whether it’s integrating Mimi into a custom speech app, running Moshi on an embedded device, or fine-tuning the model for a new voice, the streaming foundation is in place. The combination of state-of-the-art audio compression (Mimi) and a streaming speech generative model (Moshi) opens up many real-time voice AI applications, and Kyutai’s work provides the blueprint and tools to explore them.
Sources
- Kyutai Labs – Moshi GitHub Repository (architecture and streaming design)
- Kyutai Team – Moshi Open-Source Release (official release blog post with performance benchmarks)
- CTOL Digital – Kyutai Unveils Moshi: A Groundbreaking AI (full-duplex capabilities analysis)
- Reddit (r/LocalLLaMA) – Unmute by Kyutai: Make LLMs listen and speak (community discussion on performance and batching)
- Hugging Face – Mimi Model Card (usage examples and model documentation)
- Hugging Face – Moshi Documentation (Transformers integration details)
- Kyutai-Labs Moshi GitHub README (overview of implementations and models)
- Kyutai-Labs Moshi GitHub Issues (discussion of streaming usage)
- Kyutai Open-Source Release Blog Post (Mimi design and latency claims)
- Reddit announcement of Moshi (model size, latency, VRAM requirements)
- GlobalBiz article on Moshi (supported quantization and backends)
- Greenbot article on Moshi (CPU, CUDA, Metal support; 200ms latency)
- Kyutai technical report (Moshi paper) – quality evaluations and quantization artifact analysis
- LinkedIn summary of Moshi (concurrent streams, real-time interaction)
- Moshi-Swift README (iOS/Swift implementation using MLX Swift)