..
June 2025
Prompt Injection Attacks in LLM
Karpathy’s Take: LLM security is like early computing’s wild west - malicious prompts are today’s viruses, and we lack robust defenses like antivirus or proper security boundaries between agent actions.
Kimi-Dev-72B
- Model: Kimi-Dev-72B by Moonshot AI
- Repository: GitHub
- Technical Report: Coming soon
Key Features
- Achieves 60.4% performance on SWE-bench Verified for software engineering tasks
- Trained using large-scale reinforcement learning
- Autonomous repository patching in Docker environments
- Reward mechanism based on complete test suite success
- Focuses on real-world development standards and robust solutions
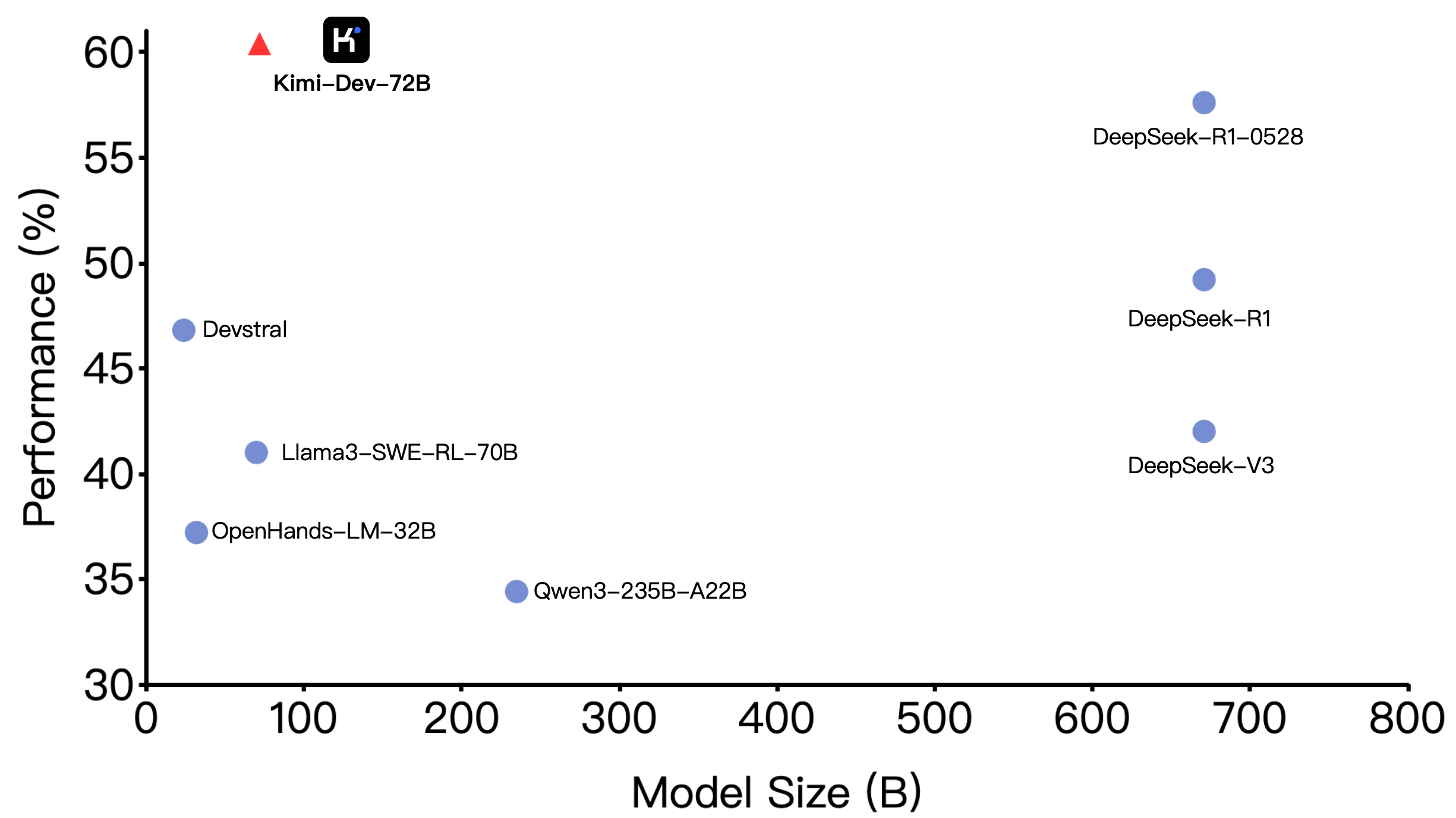
SWE-bench Verified: SWE-bench Verified is a rigorous benchmark that evaluates AI models on real-world GitHub coding issues. It uses 500 handpicked, human-validated tasks from popular Python repositories, where models must generate code patches that:
- Fix the reported issue (FAIL_TO_PASS tests)
- Maintain existing functionality (PASS_TO_PASS tests)
- Models are given only the issue description and codebase, requiring them to reason and validate solutions like real developers. This makes it a gold standard for measuring practical coding abilities.